Hoy en día, muchas empresas necesitan lidiar con una cantidad asombrosa de datos y no pueden informar sobre ellos de manera eficiente debido al volumen de datos.
Explosión de información
Primero, la explosión de información. Cada año se crean cantidades masivas de datos, y la rapidez con la que reacciona su empresa determina si tiene éxito o fracasa. Este es un gran problema y cada vez es mayor. IDC estima que el contenido digital mundial sumó hasta 487 mil millones de gigabytes en 2009. Ellos predicen que esto se duplicará en 18 meses y, a partir de entonces, cada 18 meses.
Es como una pila de DVD hasta la luna y de regreso. En una encuesta de Sloan Management en 2010, el 60% de los ejecutivos dijo que sus empresas tienen más datos de los que saben cómo utilizar de manera eficaz. Dado que los datos se duplican cada 18 meses, ese porcentaje seguirá creciendo. Según EMC, a finales de 2011 había 1,8 Zetabyte de datos digitales. 1 Zetabyte es un billón de gigabytes.
Kilobyte> Megabyte> Gigabyte> Terabyte> Petabyte> Exabyte> Zetabyte> Yottabyte
Consumerización de TI
Al mismo tiempo, la tendencia a la consumerización está impulsando las expectativas sobre lo que la TI empresarial puede ayudar a hacer. La gente quiere acceso instantáneo a la información, en el momento, ya sea un momento de riesgo o un momento de oportunidad. Si ha pasado el momento y su empresa no ha tomado las medidas adecuadas, ha fracasado. La gente quiere respuestas instantáneas. Quieren que tengan razón. Los quieren en cualquier lugar, en cualquier momento.
TI no puede cumplir
Esto pone a TI en un lugar difícil. TI no puede ofrecer lo que necesita la empresa. ¿Por qué? Porque el costo de administrar esa explosión de datos es demasiado alto. Porque no existe una forma práctica de analizar instantáneamente todo lo que sucede en relación con el negocio. TI puede entregar parte de la información. La porción más crítica de información se puede entregar casi en tiempo real. Pero no es suficiente. Los datos están creciendo. La demanda está aumentando. Debemos encontrar una manera de lidiar con esto, una manera de procesar y analizar cantidades masivas de datos en tiempo real.
Realidad con SAP HANA
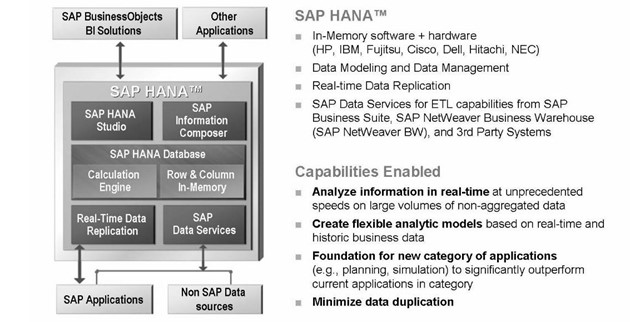
Ese es el papel de SAP HANA. Utilizando hardware y software innovadores en memoria, podemos administrar datos a escala masiva, analizarlos a una velocidad asombrosa y brindar a la empresa no solo acceso instantáneo a información transaccional en tiempo real y análisis, pero también más flexibilidad. Flexibilidad para analizar nuevos tipos de datos de diferentes formas, sin crear almacenes de datos personalizados ni mercados de datos. Incluso la flexibilidad para crear nuevas aplicaciones que antes no eran posibles.

Dispositivo SAP en memoria (SAP HANA)
Entonces, ¿qué hay dentro de HANA? Este diagrama de arquitectura explica los principales componentes y capacidades. Seguimos lanzando palabras como cantidades masivas de datos y una velocidad asombrosa. ¿Qué tipo de escala, velocidad y mejora están viendo los clientes?
Aquí hay algunos puntos de prueba:
• Primero, velocidad asombrosa. Uno de nuestros clientes piloto redujo el tiempo necesario para ejecutar un informe de una hora a un segundo. Eso es 3600 veces más rápido. Pongamos eso en perspectiva. SAP habla de ayudarlo a «ejecutar mejor», así que usemos eso como ejemplo. Cuando una persona promedio corre, se mueve a aproximadamente 7 millas por hora. 3600 veces más rápido serían unas 25.000 millas por hora. Eso es lo más rápido que haya viajado un ser humano, y solo lo hicieron una vez: los astronautas del Apolo 10, a su regreso de la luna en 1969.
• Cantidades asombrosas de datos. Durante las pruebas de HANA, ejecutamos consultas en 460 mil millones de filas de datos en menos de un segundo. Eso es como poder analizar cada visita de reparación y servicio para cada automóvil en la tierra en los últimos 12 meses, en un segundo. O para procesar cada dirección en la que todos los que viven hoy en día han vivido, en un segundo. O calcular la cantidad de impuestos pagados, por todos en el planeta, desde 1950, en un segundo.
• Y finalmente, valor asombroso. Tener la capacidad de crear nuevos procesos en tiempo real y simplificar su panorama de TI tiene un gran impacto. Según un estudio de Oxford Economics, las empresas que implementan sistemas en tiempo real ven un crecimiento promedio de ingresos del 21% y una reducción del 19% en el costo de TI.
¿Por qué esperar por los datos?
• Todos los clientes quieren ver sus datos comerciales actuales de forma inmediata y en tiempo real. Nadie quiere esperar hasta que los datos se carguen en BW.
¿Por qué esperar nuevos sistemas?
• El hardware más reciente y la tecnología de base de datos más reciente ya admiten informes en tiempo real sobre una gran cantidad de datos.
Actualización de nombres de SAP: SAP HANA
SAP HANA es un dispositivo flexible, independiente de la fuente de datos, que permite a los clientes analizar grandes volúmenes de datos de SAP ERP en tiempo real, evitando la necesidad de materializar transformaciones. El software del dispositivo SAP HANA es una combinación de hardware y software que integra una serie de componentes de SAP, incluida la base de datos de SAP HANA, el servidor de replicación de SAP LT (transformación horizontal), la conexión de extracción directa de SAP HANA (DXC) y la tecnología de replicación de Sybase. La base de datos de SAP HANA es una base de datos híbrida en memoria que combina tecnología de base de datos basada en filas, en columnas y en objetos. Está optimizado para aprovechar las capacidades de procesamiento paralelo de las arquitecturas modernas de CPU multinúcleo. Con esta arquitectura, las aplicaciones de SAP pueden beneficiarse de las tecnologías de hardware actuales.
Innovaciones de Hardware

La ley de Moores fue promulgada inicialmente en 1965. Según esta ley, «el número de transistores en un chip se duplica cada año». Sin embargo, en 1975 esto fue ajustado por David House, quien dijo que se duplicará cada dos años. Una variante generalizada de la ley de Moore establece que los transistores se duplicarán cada 18 meses.
Mejoras en la tecnología
Históricamente, los sistemas de bases de datos se diseñaron para funcionar bien en sistemas informáticos con RAM limitada, esto tuvo el efecto de que la E / S de disco lenta era el principal cuello de botella en el rendimiento de datos. En consecuencia, la arquitectura de esos sistemas se diseñó con un enfoque en la optimización del acceso al disco, por ejemplo, minimizando el número de bloques de disco (o páginas) que se leerán en la memoria principal al procesar una consulta.
La arquitectura de la computadora ha cambiado en los últimos años. Ahora las CPU de varios núcleos (varias CPU en un chip o en un paquete) son estándar, con una comunicación rápida entre los núcleos del procesador que permite el procesamiento en paralelo. La memoria principal ya no es un recurso limitado, los servidores modernos pueden tener 2 TB de memoria del sistema y esto permite que las bases de datos completas se mantengan en la RAM. Actualmente, los procesadores de servidor tienen hasta 64 núcleos y pronto estarán disponibles 128 núcleos. Con el creciente número de núcleos, las CPU pueden procesar más datos por intervalo de tiempo. Esto cambia el cuello de botella de rendimiento de la E / S del disco a la transferencia de datos entre la memoria caché de la CPU y la memoria principal.
Entender el almacenamiento de datos de la columna
El concepto de almacenamiento de datos de columna se ha utilizado durante bastante tiempo. Históricamente, se utilizó principalmente para análisis y almacenamiento de datos, donde las funciones agregadas juegan un papel importante. El uso de almacenes de columnas en aplicaciones OLTP requiere un enfoque equilibrado para la inserción e indexación de datos de columna para minimizar las pérdidas de caché. La base de datos de SAP HANA permite al desarrollador especificar si una tabla se almacenará en columnas o en filas. También es posible modificar una tabla existente de columna a basada en filas y viceversa.
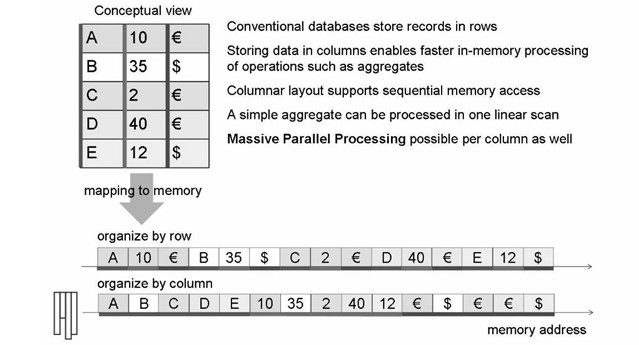
Optimización rápida del lado del software para la memoria
Conceptualmente, una tabla de base de datos es una estructura de datos bidimensional con celdas organizadas en filas y columnas. Sin embargo, la memoria de la computadora está organizada como una estructura lineal. Para almacenar una tabla en la memoria lineal, existen dos opciones, un almacenamiento orientado a filas almacena una tabla como una secuencia de registros, cada uno de los cuales contiene los campos de una fila. Por otro lado, en un almacén de columnas, las entradas de una columna se almacenan en ubicaciones de memoria contiguas.
Datos clave: ¿Cuándo usar Row Store, cuándo Column Store?
Row Store
Si desea informar sobre todas las columnas, el almacenamiento de filas es más adecuado porque reconstruir la fila completa es una de las operaciones de almacenamiento de columnas más costosas.
Column Store
Si desea llenar la tabla con grandes cantidades de datos, que deben agregarse y analizarse, entonces un almacén de columnas es más adecuado.
Procesamiento paralelo
Los datos solo se bloquean parcialmente, por lo que es posible el procesamiento en paralelo. Por lo tanto, diferentes núcleos pueden procesar columnas individuales.

La base de datos de SAP HANA tiene componentes de varias otras aplicaciones de software.
Por ejemplo:
• Row Store y SQL Parser tienen algo de código de la base de datos P & time
• Column Store tiene código de BWA Trex Engine
• La capa de persistencia (volúmenes de datos y registros) tiene código de MAX DB
La solución de implementación rápida le permite implementar un contenido predefinido y pre-acondicionado en varios perímetros funcionales o técnicos diferentes. Permiten responder rápidamente a las expectativas a través del contenido entregado por SAP.
